Explaining the SDG classifier
At Impacter we developed a machine learning classifier to calculate what Sustainable Development Goals (SDG’s) are related to a given abstract. Read the blog post about SDG’s to learn more about how we did this. In short, current methods to classify texts often use Boolean Queries: looking for the presence of certain words, or combinations of words, to determine if an abstract belongs to a certain SDG. This has some major downsides: it can not handle synonyms, and it is hard to enhance or change them. The deep learning model on the other hand, can handle synonyms, it also considers the entire sentence it is looking at.
But a deep learning model does not only have upsides. There are also some major downsides to such models. They are more expensive to run than a Boolean Query, so we need a good reason to use the deep learning model instead of the Boolean Query. It is also harder to understand why the model makes certain decisions. For our users, and for ourselves, it's important to understand why such a model makes a specific decision in order to be able to have confidence in the tool. Fortunately, in recent years, methods have been developed to gain better understanding of deep learning models.
We chose to use a method which focused on the individual words, because this allows us to easily compare the model with the Boolean Queries. Although there are other methods that focus more on the relations between words, at specific stages in the model. With the method we chose, we can ask the model: what is the contribution of each word to a specific SDG. So for example, if we have an abstract which is related to SDG 4: Quality Education, we can ask how important each word is (See image). As you can see, both literacy and children are deemed important by the model.

This single example gives some confidence in the method. It seems fairly reasonable that literacy and children are important words when determining if an abstract relates to the goal about Quality Education. Although this does not give a broader insight into the workings of the model. In order to get a broader understanding of the model, we collected the word-importances for a larger collection of abstracts (around 13.000). Using this data, it was possible to create lists of the most important words for each of the sustainable development goals. For example, the top words for Quality Education are: literacy, competence, sustainable, deaf, empower and disabilities. All these words are clearly related in some way to the goal.
Finally, to understand if the model does actually do something extra, we compared the list of important words with a list of all words used in the boolean query. Does the model use other words than we find in the query? Or are the top lists basically the same as the boolean query list?
In the image below, we show for multiple SDG's the most important words. In the upper part of the image you see the top 10 most important words, according to the model, that are not present in the list of words used in the Boolean Query. The lower part of the image shows the words that are present in the Boolean Query. The Boolean Queries generally have more words then just this list, but those words were not deemed important enough by the model.
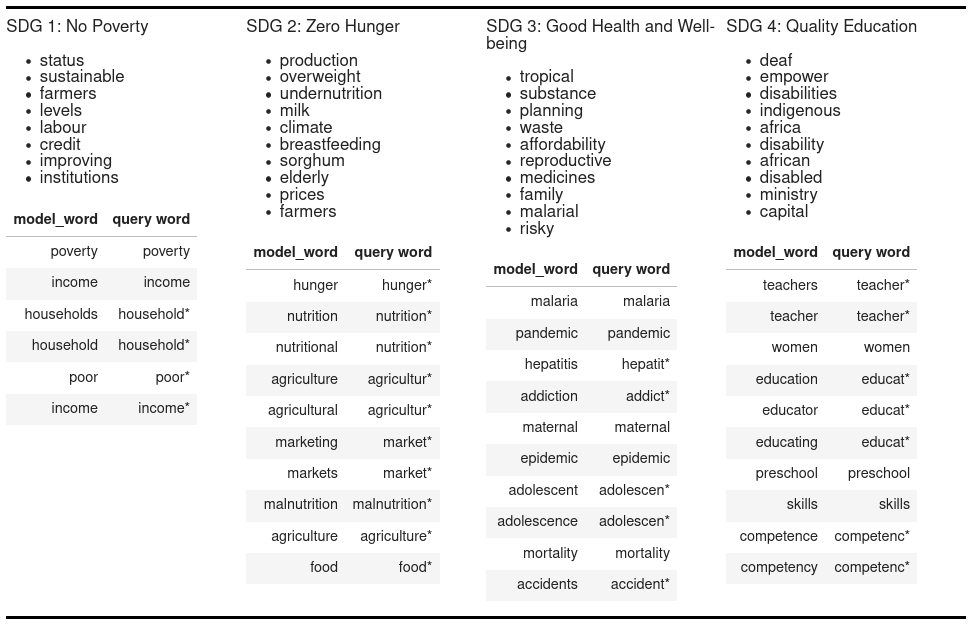
As we see in this image, the words the model finds all look really reasonable. So, having looked at the model using the explainable AI technique. We can now answer the question: Yes, the model does do something extra, it can use the context of words to make a better decision. And no, the model does not simply recreate the Boolean Query nor does it show strange behaviour.
For us, enough reason to actually implement the SDG classifier into Impacter. So in the coming years, all our users can benefit from our classifier when writing a Horizon Europe grant. Curious to see how it works? Reach out to Paul and we’ll schedule a demo!